Building Large Language Models
Rohan Paul Substack is a detailed resource of in-depth explanations about LLMs and how to build them.
Lamini: a tailored (private) LLM engine
Jay Alammar: The Illustrated GPT-2 (Visualizing Transformer Language Models)…
Large Language Model Course is divided into three parts:
- 🧩 LLM Fundamentals covers essential knowledge about mathematics, Python, and neural networks.
- 🧑🔬 The LLM Scientist focuses on learning how to build the best possible LLMs using the latest techniques
- 👷 The LLM Engineer focuses on how to create LLM-based solutions and deploy them.
Early Access Manning book on Build a Large Language Model (From Scratch) Github: @raspt 
Transformers from Scratch Matt Diller’s step-by-step, with Colab ## Examples
TI-84 GPT4All and Youtube
How to add custom GPTs to any website in minutes.
Libraries
Run a variety of LLMs locally using Ollama
To run Llama 3 locally, Download Ollama and run llama3:
ollama run llama3
Collecting Data
Scripts to convert Libgen to txt (see also Explaining LLMs) ## Technical Details
from my question to Metaphor.systems
https://jalammar.github.io/illustrated-transformer/ https://huggingface.co/
Google’s free BERT model, a small-sized model for language
How to Build
Understanding LLMs: A Comprehensive Overview from Training to Inference
2023 summary from Simon Willison: a good list of resources for how to build your own LLM.
step-by-step tutorial for How to build LLama3 from scratch with code and diagrams

The Mathematics of Training LLMs — with Quentin Anthony of Eleuther AI
deep dive into the viral Transformers Math 101 article and high-performance distributed training for Transformers-based architectures.
An observation on Generalization: 1 hr talk by Ilya Sutskever, OpenAI’s Chief scientist. He’s previously talked about how compression may be all you need for intelligence. In this lecture, he builds on the ideas of Kolmogorov complexity and how neural networks are implicitly seeking for simplicity in the representations that they learn. He provides a clarity of thought that is rarely seen in the industry around generalization of these novel systems.
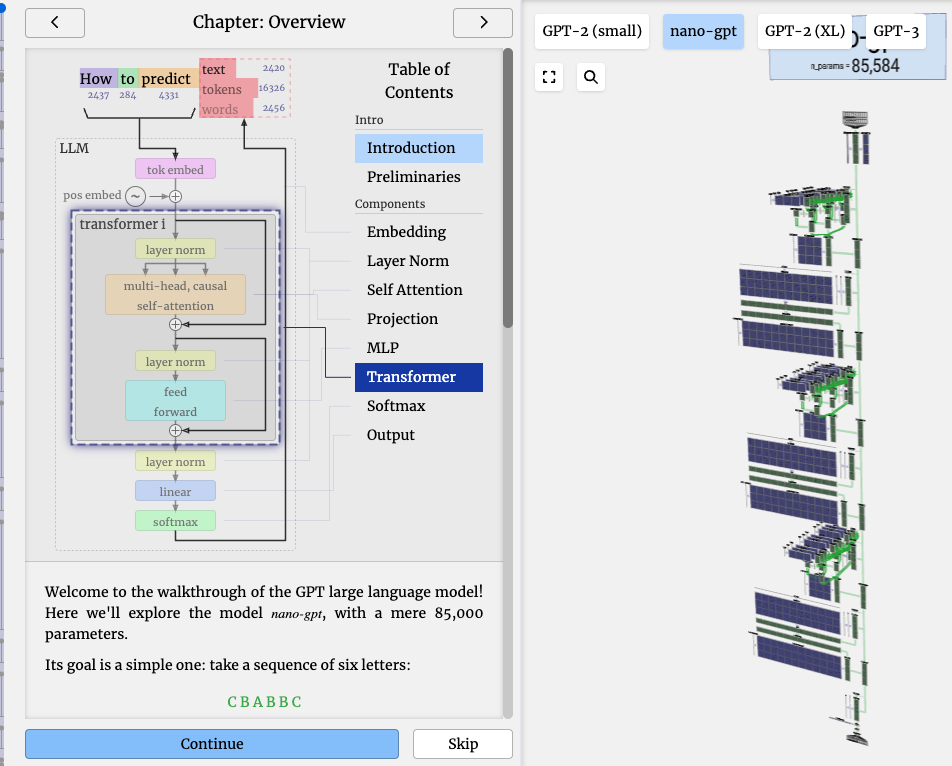
Brendan Bycroft wrote a well-done step-by-step visualization of how an LLM works
Welcome to the walkthrough of the GPT large language model! Here we’ll explore the model nano-gpt, with a mere 85,000 parameters.
Its goal is a simple one: take a sequence of six letters:
C B A B B C and sort them in alphabetical order, i.e. to “ABBBCC”.
Operations
This blog post from Meta outlines the infrastructure being used to train Llama 3. It talks through storage, networking, Pytorch, NCCL, and other improvements. This will lay the foundation for Meta’s H100s coming online throughout the rest of this year.
